Ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取。
对象数据的底层存储服务是由多个主机(host)组成的存储系统,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠,自动化,分布式对象存储系统。
librados是RADOS存储集群的API,它支持C,C++,Java,Python,Ruby和PHP等编程语言。
由于直接基于librados这个API才能使用Ceph集群的话对使用者是有一定门槛的。当然,这一点Ceph官方也意识到了,于是他们还对Ceph做出了三个抽象资源,分别为RADOSGW,RBD,CEPHFS等。
RadosGw,RBD和CephFS都是RADOS存储服务的客户端,他们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用不同的应用场景.
它是一个更抽象的能够跨互联网的云存储对象,它是基于RESTful风格提供的服务。每一个文件都是一个对象,而文件大小是各不相同的。
他和Ceph集群的内部的对象(object,它是固定大小的存储块,只能在Ceph集群内部使用,基于RPC协议工作的)并不相同。
值得注意的是,RadosGw依赖于librados哟,访问他可以基于http/https协议来进行访问。
将ceph集群提供的存储空间模拟成一个又一个独立的块设备。每个块设备都相当于一个传统磁(硬)盘一样,你可以对它做格式化,分区,挂载等处理。
值得注意的是,RBD依赖于librados哟,访问需要Linux内核支持librdb相关模块。
很明显,这是Ceph集群的文件系统,我们可以很轻松的像NFS那样使用,但它的性能瓶颈相比NFS来说是很难遇到的。
值得注意的是,CephFS并不依赖于librados哟,它和librados是两个不同的组件。但该组件使用的热度相比RadosGw和RBD要低。
查看ceph的官方文档:
https://docs.ceph.com/en/latest/
中文社区文档:
(1)CRUSH算法是Ceph内部数据对象存储路由的算法。它没有中心节点,即没有元数据中心服务器。
(2)无论使用librados,RadosGw,RBD,CephFS哪个客户端来存储数据,最终的数据都会被写入到Rados Cluster,值得注意的是这些客户端和Rados Cluster之间应该有多个存储池(pool),每个客户端类型都有自己的存储池资源。
http://docs.ceph.org.cn/glossary/#term-56
(1)Rados Cluster集群固定大小的object可能不符合我们要存储某个大文件,因此一个大文件想要存储到ceph集群,它可能会被拆分成多个data object对象进行存储;
(2)通常情况下data object请求向某个pool存储数据时,通过CRUSH算法会先对data object进行一致性哈希计算,而后将存储任务映射到到该pool中的某个PG上;
(3)紧接着,CRUSH算法(是用来完成object存储路由的一个算法)会根据pool的冗余副本数量和data object的存储类型找到足量的OSD进行存储,当然对应的PG是有active PG和standby PG角色之分的,通常副本数我们会设置为3;
由多台服务器组成
英文全称为"Object Storage Device",即对象存储设备,通常指的是磁盘设备,它是真正负责存储数据的设备。一台服务器上可能有多块磁盘存储设备,这属于正常现象。
通常我们需要关心以下几点:
(1)ceph OSD(object storage daemon,进程名称为"ceph-osd")存储数据、处理数据复制、恢复、重新平衡,并通过检查其他ceph OSD守护进程的心跳向ceph监控器和管理器提供一些监视信息;
(2)为了实现冗余和高可用性,通常至少需要三个Ceph osd,因为默认数据副本是3个。
全称为"monitor",即监视器,也就是我们所说的集群元数据节点(而非文件元数据)。它是用来管理整个ceph集群的运行状态(比如集群有多少台服务器,每个服务器有多少OSD及其状态信息等等)。
它是为了能够让整个集群能够正常运行而设计的角色,因此为了避免该角色存在单点故障,因此会配置高可用集群,其底层基于POSIX协议实现。
通常我们需要关注以下几点:
(1)Ceph Monitor(进程名称为"Ceph-mon")维护集群状态的映射,包括Monitor映射、manager映射、OSD映射,CRUSH映射和PG映射等;
(2)这些映射是Ceph守护进程相互协调所需的关键集群状态,例如哪些OSD是正常工作的状态,哪些PG不可用等等;
(3)监视器还负责管理守护程序和客户端之间的身份验证(基于Cephx协议实现);
(4)为了实现冗余和高可用性,通常至少需要三个监视器,这不仅仅提供了高可用性,还提供了负载均衡的能力,因为通常Monitors还扮演着"身份验证"的角色,如果配置多个监视器可以很好的进行负载均衡。
全称为"manager",即管理者。它的作用就是用来维护查询类的操作,它将很多查询操作按照自己的方式先缓存下来,一旦有人做监控,它能做及时的响应。有点类似于zabbix agent的功能。
早期ceph的版本是没有mgr组件的,但由于mon组件每次读取数据都是实时查询的,这种代价很高昂,而监控集群又是必须的,因此在ceph的L版本引入了mgr组件。
通常我们需要关注以下几点:
(1)ceph管理器守护程序(进程名称为"ceph-mgr")负责跟踪运行时度量和ceph集群的当前状态,包括存储利用率、当前性能度量和系统负载;
(2)Ceph管理器守护进程还托管基于python的插件来管理和Rest API;
(3)高可用性通常至少需要两个管理器;
存储池,存储池的大小取决于底层的OSD的存储空间大小。一个ceph集群是可以由多个存储池构成的,而且每个存储池还可以被划分为多个不同的名称空间,而且每个名称空间可以划分成多个PG资源。
全称为"placement groups",即安置组。注意哈,Pool和PG都是抽象的概念,即实际上并不存在,它是一个虚拟的概念。我们暂时可以理解他是用来存储数据的安置组即可。
(类似于HDFS的namenode,如果不用cephfs,该组件可以不安装)【可选组件】
全称为"MetaData Server",即对应cephfs文件系统的元数据服务器。如果你不需要使用cephfs可以不安装哟,如果要用的话,建议安装多个节点,以免出现单点故障的情况。
从严格意义上来讲,MDS只能算作构建于Rados存储集群之上的文件存取接口,它同RBD和RadowGW属于同一个级别,而非Ceph的基础组件。
但它却是ceph的第一个(最初也是除librados API之外的唯一一个)客户端数据存取组件。
通常我们需要关心以下几点:
(1)Ceph元数据服务器(MDS,进程名称为"ceph-mds")代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS);
(2)Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls、find等),而不会给Ceph存储集群带来巨大负担;
对象存储网关,用于对象存储系统,也是需要启用相关组件模块。
(1)如果我们给定的存储路径是一块裸的物理磁盘(我们称之为"裸设备",也就是该设备没有被格式化指定的文件系统),则ceph是可以直接来进行管理的,只不过它使用的是bluestore存储引擎。
(2)通常情况下我们的ceph集群会有OSDs,Monitors,Managers和MDSs这几个基础组件,其中MDSs是可选的组件。
(3)RBD不需要通过运行守护进程来提供服务的,它基于librbd模块,它提供了相应的API来进行使用。
ceph是目前业内比较普遍使用的开源分布式存储系统,实现有多种类型的本地存储系统;在较早的版本当中,ceph默认使用FileStore作为后端存储,但是由于FileStore存在一些缺陷,重新设计开发了BlueStore,并在L版本之后作为默认的后端存储。
从Ceph Luminous v12.2.z 开始,默认采用了新型的BlueStore作为Ceph OSD后端,用于管理存储磁盘。
BlueStore的优势:
(1)对于大型写入操作,避免了原先FileStore的两次写入(注意,很多FileStore将journal日志存放到独立到SSD上,也能够获得类似的性能提升,不过分离journal的部署方式是绕开FileStore的短板);
(2)对于小型随机写入,BlueStore比 FileStore with journal性能还要好对于Key/value数据BlueStore性能明显提升;
(3)当集群数据接近爆满时,BlueStore避免了FileStore的性能陡降问题;
(4)在BlueStore上使用raw库的小型顺序读性能有降低,和BlueStore不采用预读(readahead)有关,但可以通过上层接口(如RBD和CephFS)来实现性能提升;
(5)BlueStore在RBD卷或CephFS文件中采用了copy-on-write提升了性能;
BlueStore是在底层裸块设备上建立的存储系统,内建了RocksDB key/value 数据库用于管理内部元数据。一个小型的内部接口组件称为BludFS实现了类似文件系统的接口,以便提供足够功能让RocksDB来存储它的”文件”并向BlueStroe共享相同的裸设备。
推荐阅读:
https://cloud-atlas.readthedocs.io/zh_CN/latest/ceph/bluestore.html
推荐阅读: https://docs.ceph.com/en/latest/install/#installing-ceph
(1)ceph-deploy是一种部署ceph的方法,它仅依赖于SSH访问服务器、而后借助sudo和一些Python模块就可以实现部署。
(2)它完全在工作站(管理主机)上运行,不需要任何服务、数据库或类似的东西。
(3)它不是一个通用的部署系统,它只是为Ceph设计的,并且是为那些希望在不需要安装Chef、Puppet或Juju的情况下使用合理的初始设置快速运行Ceph的用户而设计的。
(4)除了推送Ceph配置文件之外,它不会处理客户端配置,想要对安全设置、分区或目录位置进行精确控制的用户应该使用Chef或Puppet之类的工具。
(1)我们可以使用ansible的playbook来部署Ceph;
(2)ceph的GitHub地址为: "https://github.com/ceph/ceph-ansible"
对应的GitHub地址: "https://github.com/ceph/ceph-chef"
即使用puppet工具来部署ceph。
和k8s的kubeadm一样好用,部署服务非常方便,推荐使用。
参考链接: https://docs.ceph.com/en/latest/install/#other-methods
推荐阅读: https://docs.ceph.com/en/latest/releases/general/#understanding-the-release-cycle
ceph的发行版本说明
开发版本,一般是用于内部测试。
测试版本,一般是开发人员测试使用。
稳定版本,生产环境中推荐使用。
1.cephadm基础配置环境准备
1.1 基于cephadm部署前提条件,官方提的要求Ubuntu 22.04 LTS出了容器运行时其他都满足
- Python 3
- Systemd
- Podman or Docker for running containers
- Time synchronization (such as Chrony or the legacy ntpd)
- LVM2 for provisioning storage devices
参考链接: https://docs.ceph.com/en/latest/cephadm/install/#requirements
| 主机 | ip | 配置 |
|---|---|---|
| ceph141 | 10.0.0.141 | CPU: 1c Memory: 2G /dev/sdb:300GB /dev/sdc: 500GB /dev/sdd: 1024GB |
| ceph142 | 10.0.0.142 | CPU: 1c Memory: 2G /dev/sdb:300GB /dev/sdc: 500GB /dev/sdd: 1024GB |
| ceph143 | 10.0.0.143 | CPU: 1c Memory: 2G /dev/sdb:300GB /dev/sdc: 500GB /dev/sdd: 1024GB |
lsblk

timedatectl set-timezone Asia/Shanghai
略
cat >> /etc/hosts <<EOF
10.0.0.141 ceph141
10.0.0.142 ceph142
10.0.0.143 ceph143
EOF
Ubuntu系统可跳过
CEPH_RELEASE=19.2.2
curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
[root@ceph141 ~]# mv cephadm-v19.2.2 /usr/local/bin/cephadm
[root@ceph141 ~]# chmod +x /usr/local/bin/cephadm
[root@ceph141 ~]# cephadm version
docker load -i

[root@ceph141 ~]# cephadm bootstrap --mon-ip 10.0.0.141 --cluster-network 10.0.0.0/24 --allow-fqdn-hostname --skip-pull
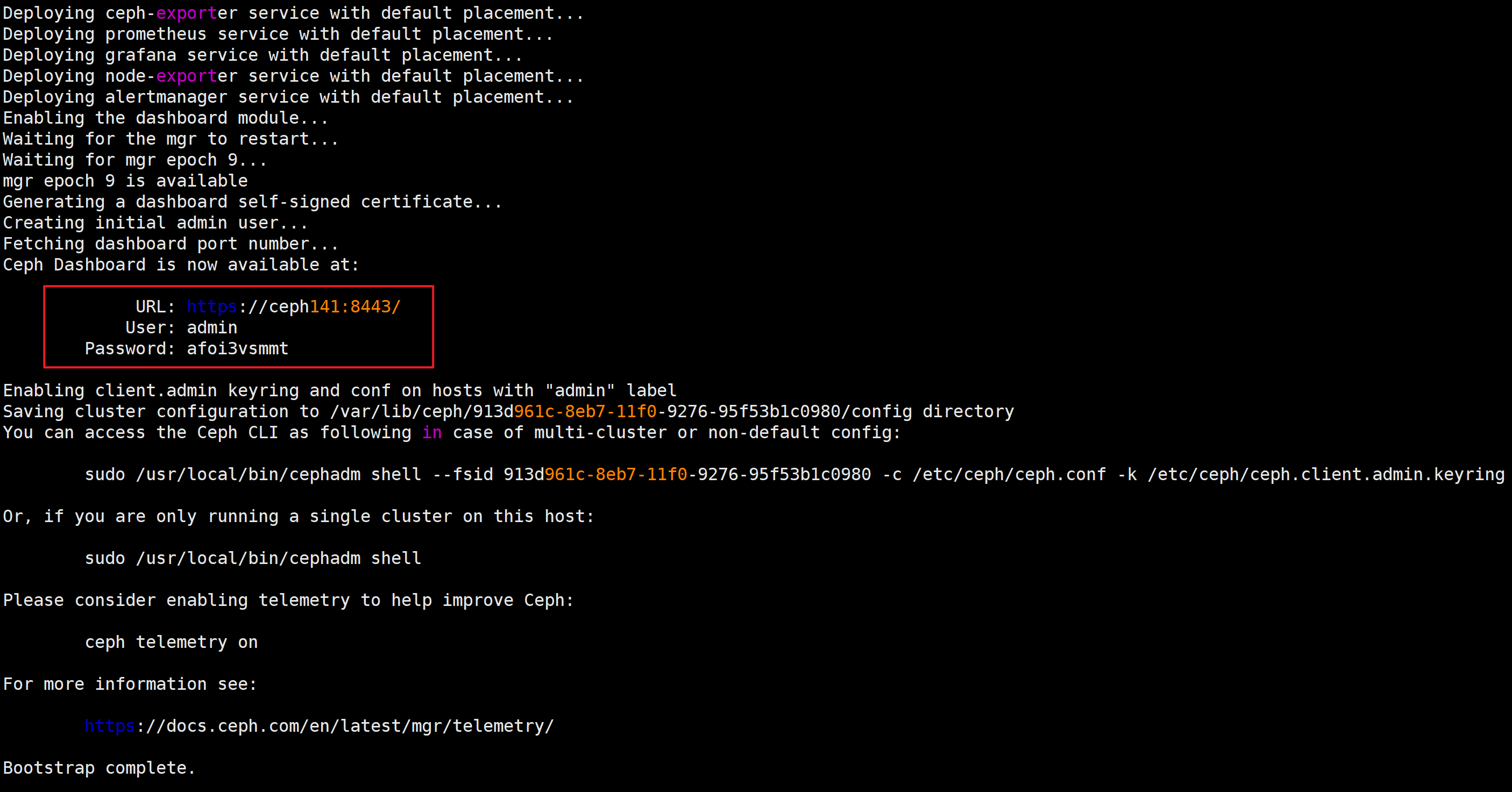
https://ceph141:8443/
除了上面在WebUI的方式修改密码外,也可以基于命令行方式修改密码,只不过在应用时可能需要等待一段时间才能生效。【目前官方已经弃用,大概需要等30s-1min】
[root@ceph141 ~]# echo zhubaolin | ceph dashboard set-login-credentials admin -i -
******************************************************************
*** WARNING: this command is deprecated. ***
*** Please use the ac-user-* related commands to manage users. ***
******************************************************************
Username and password updated
[root@ceph141 ~]#
1.添加软件源
[root@ceph141 ~]# cephadm add-repo --release squid
Installing repo GPG key from https://download.ceph.com/keys/release.gpg...
Installing repo file at /etc/apt/sources.list.d/ceph.list...
Updating package list...
Completed adding repo.
[root@ceph141 ~]# ll /etc/apt/sources.list.d/ceph.list
-rw-r--r-- 1 root root 55 Mar 31 16:38 /etc/apt/sources.list.d/ceph.list
[root@ceph141 ~]# ll /etc/apt/trusted.gpg.d/ceph.release.gpg
-rw-r--r-- 1 root root 1143 Mar 31 16:38 /etc/apt/trusted.gpg.d/ceph.release.gpg
[root@ceph141 ~]# ll /etc/ceph/
total 20
drwxr-xr-x 2 root root 4096 Mar 31 15:37 ./
drwxr-xr-x 130 root root 4096 Mar 31 15:30 ../
-rw------- 1 root root 151 Mar 31 15:37 ceph.client.admin.keyring
-rw-r--r-- 1 root root 171 Mar 31 15:37 ceph.conf
-rw-r--r-- 1 root root 595 Mar 31 15:33 ceph.pub
[root@ceph141 ~]#
[root@ceph141 ~]# sed -i 's#download.ceph.com#mirrors.aliyun.com/ceph#' /etc/apt/sources.list.d/ceph.list
[root@ceph141 ~]#
[root@ceph141 ~]# cat /etc/apt/sources.list.d/ceph.list
deb https://mirrors.aliyun.com/ceph/debian-squid/ jammy main
[root@ceph141 ~]#
参考链接:
https://developer.aliyun.com/mirror/ceph
2.安装ceph通用工具包
[root@ceph141 ~]# apt update
[root@ceph141 ~]# apt -y install ceph-common
3.测试使用
[root@ceph141 ~]# ceph version
ceph version 19.2.2 (58a7fab8be0a062d730ad7da874972fd3fba59fb) squid (stable)
[root@ceph141 ~]#
[root@ceph141 ~]# ceph -s
cluster:
id: 11e66474-0e02-11f0-82d6-4dcae3d59070
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph141 (age 69m)
mgr: ceph141.mbakds(active, since 65m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0 root default
[root@ceph141 ~]#
[root@ceph141 ~]# ceph version
ceph version 19.2.2 (0eceb0defba60152a8182f7bd87d164b639885b8) squid (stable)
1.启动shell工具
[root@ceph141 ~]# cephadm shell
Inferring fsid 0d0ea8c6-8eb3-11f0-9e83-d760effd8823
Inferring config /var/lib/ceph/0d0ea8c6-8eb3-11f0-9e83-d760effd8823/mon.ceph141/config
Not using image 'sha256:4892a7ef541bbfe6181ff8fd5c8e03957338f7dd73de94986a5f15e185dacd51' as it s not in list of non-dangling images with ceph=True label
root@ceph141:/#
root@ceph141:/#
root@ceph141:/# ceph --version
ceph version 19.2.3 (c92aebb279828e9c3c1f5d24613efca272649e62) squid (stable)
root@ceph141:/#
root@ceph141:/# ceph version
ceph version 19.2.2 (0eceb0defba60152a8182f7bd87d164b639885b8) squid (stable)
root@ceph141:/#
root@ceph141:/# ceph -s
cluster:
id: 0d0ea8c6-8eb3-11f0-9e83-d760effd8823
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph141 (age 65m)
mgr: ceph141.qiwvvr(active, since 61m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
root@ceph141:/#

本质上是启动了一个容器
建议将docker和镜像重新从ceph141节点导入到ceph142和ceph143节点
scp alertmanager-v0.25.0.tar.gz ceph-v19.tar.gz grafana-v10.4.0.tar.gz node-exporter-v1.7.0.tar.gz prometheus-v2.51.0.tar.gz 10.0.0.142:~
scp alertmanager-v0.25.0.tar.gz ceph-v19.tar.gz grafana-v10.4.0.tar.gz node-exporter-v1.7.0.tar.gz prometheus-v2.51.0.tar.gz 10.0.0.143:~
for i in alertmanager-v0.25.0.tar.gz ceph-v19.tar.gz grafana-v10.4.0.tar.gz node-exporter-v1.7.0.tar.gz prometheus-v2.51.0.tar.gz; do docker load -i $i ;done
[root@ceph141 ~]# ceph orch host ls

[root@ceph141 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub ceph142
[root@ceph141 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub ceph143
[root@ceph141 ~]# ceph orch host add ceph142 10.0.0.142
Added host 'ceph142' with addr '10.0.0.142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host add ceph143 10.0.0.143
Added host 'ceph143' with addr '10.0.0.143'
[root@ceph141 ~]#
温馨提示:
将集群加入成功后,会自动创建"/var/lib/ceph/<Ceph_Cluster_ID>"相关数据目录。
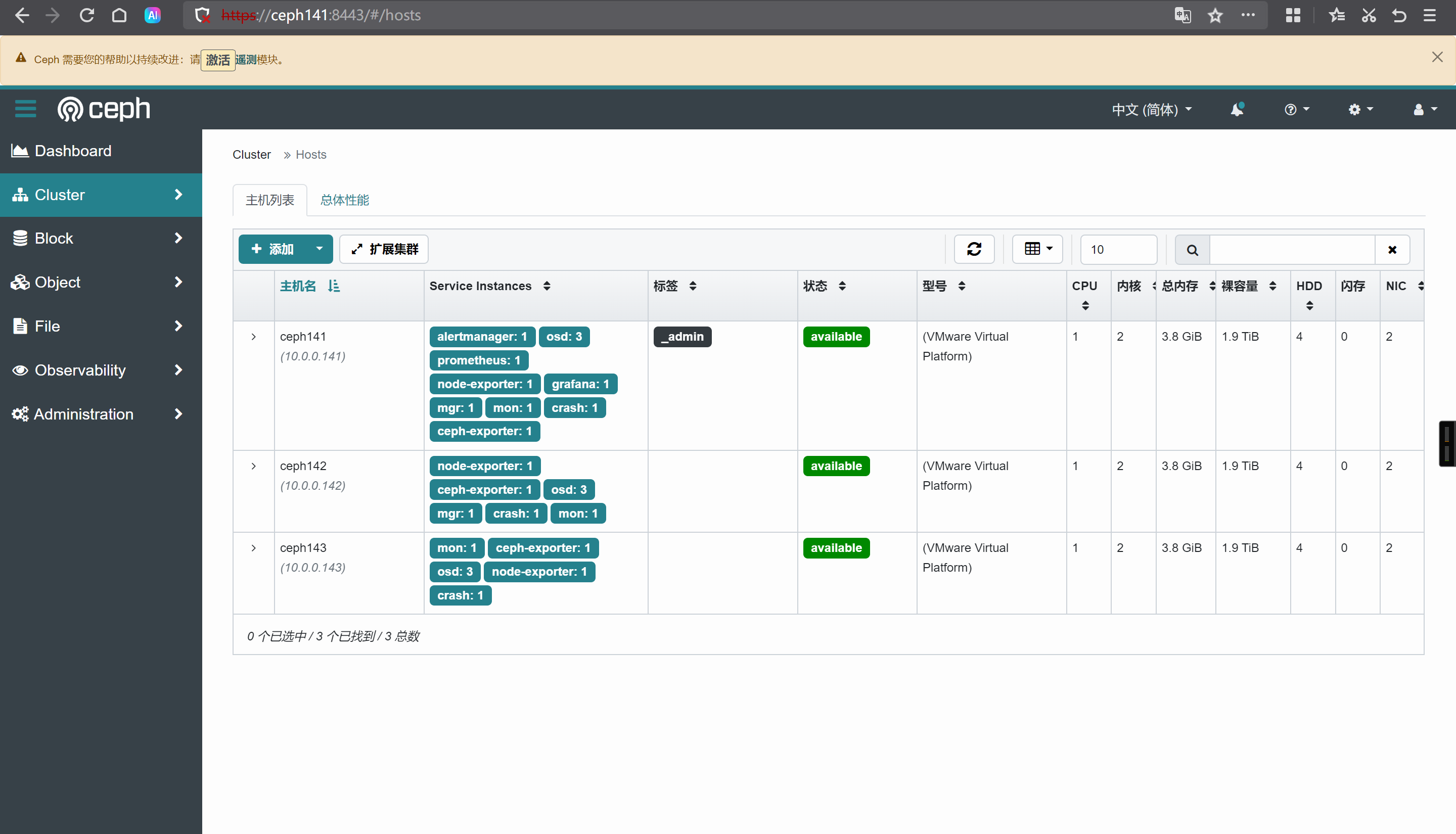
[root@ceph141 ~]# ceph orch host ls

https://ceph141:8443/#/hosts
[root@ceph141 ~]# ceph orch host drain ceph143
Scheduled to remove the following daemons from host 'ceph143'
type id
-------------------- ---------------
node-exporter ceph143
mon ceph143
ceph-exporter ceph143
crash ceph143
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
ceph143 10.0.0.143 _no_schedule,_no_conf_keyring
3 hosts in cluster
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host drain ceph143
Scheduled to remove the following daemons from host 'ceph143'
type id
-------------------- ---------------
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host rm ceph143
Removed host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
2 hosts in cluster
[root@ceph141 ~]#
[root@ceph143 ~]# ll /var/lib/ceph/
total 12
drwxr-xr-x 3 root root 4096 Mar 31 17:02 ./
drwxr-xr-x 62 root root 4096 Mar 31 17:02 ../
drwx------ 4 167 167 4096 Mar 31 17:08 11e66474-0e02-11f0-82d6-4dcae3d59070/
[root@ceph143 ~]#
[root@ceph143 ~]#
[root@ceph143 ~]# ll /var/log/ceph/
total 112
drwxr-xr-x 3 root root 4096 Mar 31 17:05 ./
drwxrwxr-x 10 root syslog 4096 Mar 31 17:02 ../
drwxrwx--- 2 167 167 4096 Mar 31 17:06 11e66474-0e02-11f0-82d6-4dcae3d59070/
-rw-r--r-- 1 root root 96321 Mar 31 17:09 cephadm.log
[root@ceph143 ~]#
为了实验效果,我还是将ceph143加回来
[root@ceph141 ~]# ceph orch host add ceph143 10.0.0.143
Added host 'ceph143' with addr '10.0.0.143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
ceph143 10.0.0.143
3 hosts in cluster
[root@ceph141 ~]#
温馨提示:
如果一个设备想要加入ceph集群,要求满足3个条件:
1.设备未被使用;
2.设备的存储大小必须大于5GB;
3.需要等待一段时间,快则30s,慢则3分钟
ceph orch device ls
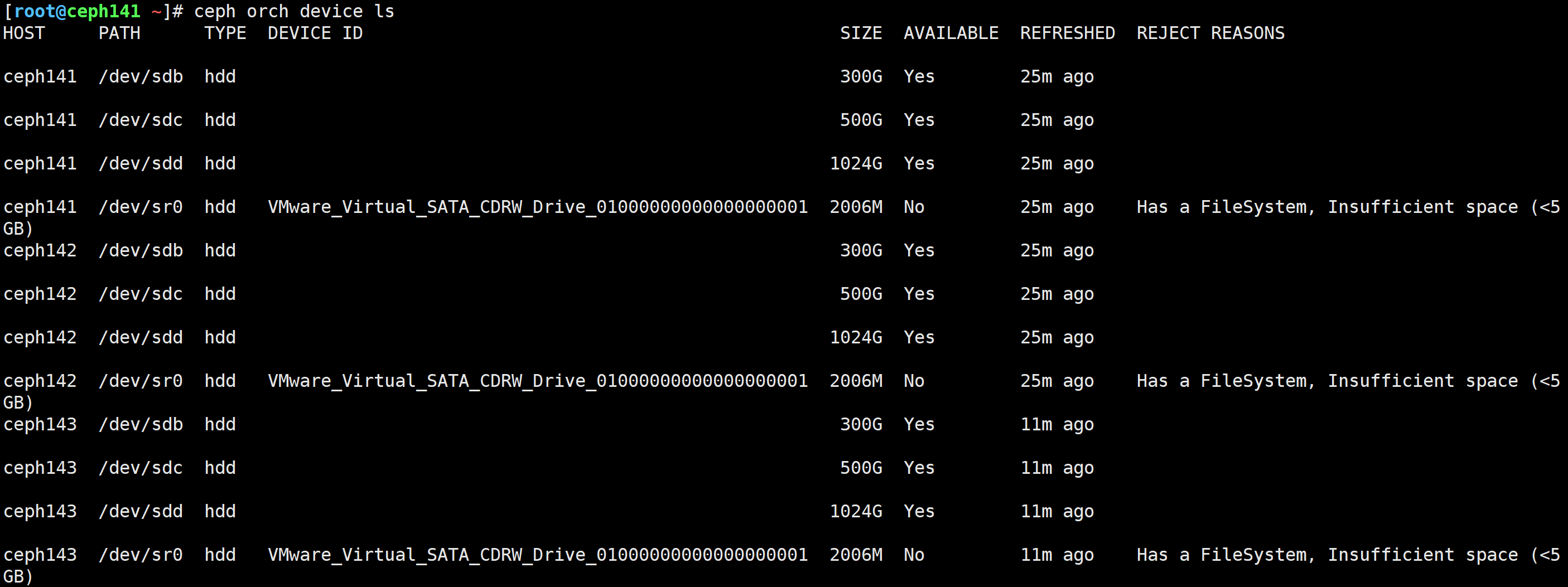
lsblk
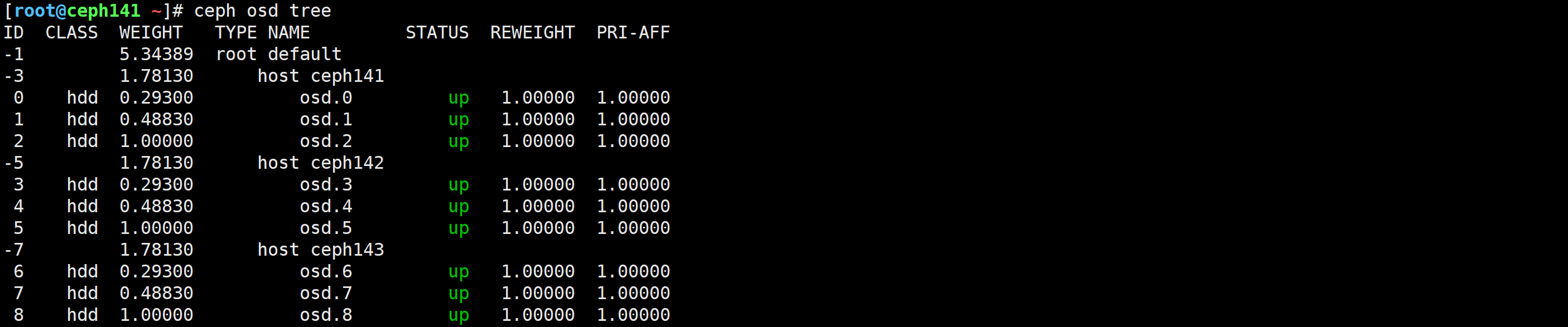
[root@ceph141 ~]# ceph osd tree
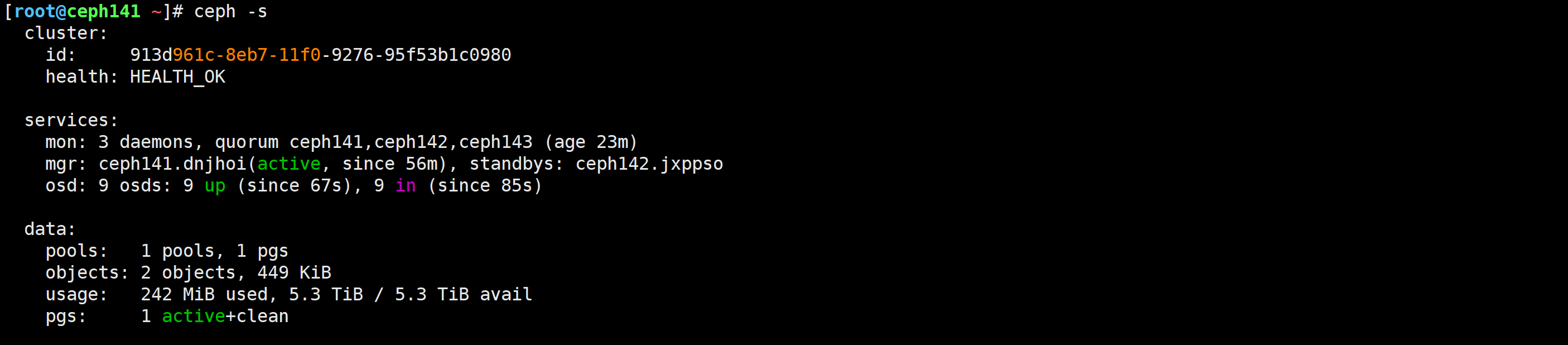
[root@ceph141 ~]# ceph -s

[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdb
Created osd(s) 0 on host 'ceph141'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdc
Created osd(s) 1 on host 'ceph141'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdd
Created osd(s) 2 on host 'ceph141'
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdb
Created osd(s) 3 on host 'ceph142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdc
Created osd(s) 4 on host 'ceph142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdd
Created osd(s) 5 on host 'ceph142'
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdb
Created osd(s) 6 on host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdc
Created osd(s) 7 on host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdd
Created osd(s) 8 on host 'ceph143'
[root@ceph141 ~]#
温馨提示:
1.此步骤会在"/var/lib/ceph/<Ceph_Cluster_ID>/osd.<OSD_ID>/fsid"文件中记录对应ceph的OSD编号对应本地的磁盘设备标识。
2.比如查看ceph142节点的硬盘和OSD的对应关系如下:
[root@ceph142 ~]# ll /var/lib/ceph/913d961c-8eb7-11f0-9276-95f53b1c0980/osd.*/fsid

[root@ceph141 ~]# ceph osd tree
[root@ceph141 ~]# ceph -s
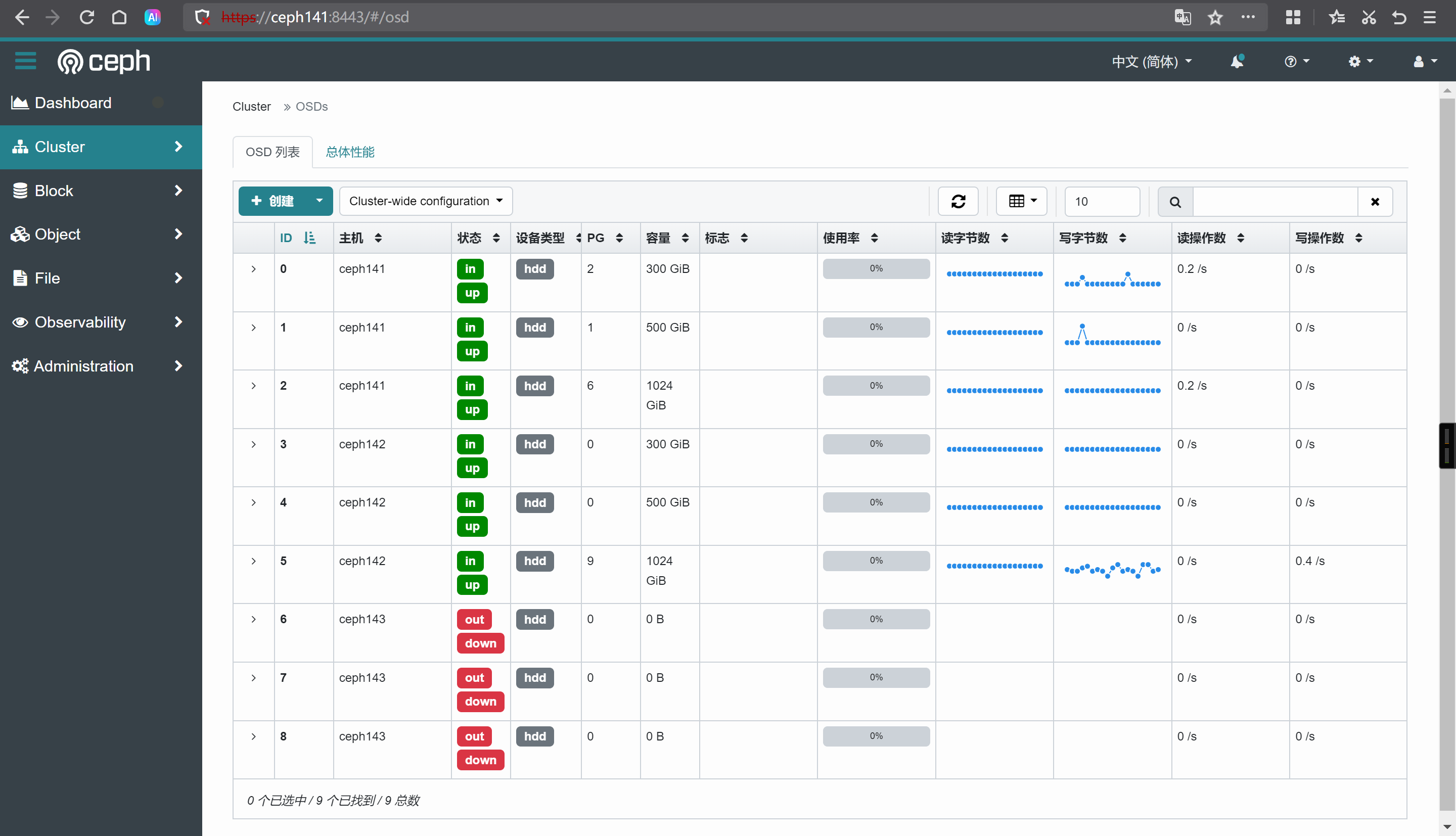
https://ceph141:8443/#/osd
[root@ceph141 ~]# ceph osd pool ls
.mgr
[root@ceph141 ~]# ceph osd pool create zhubl
pool 'zhubl' created
[root@ceph141 ~]# ceph osd pool ls
.mgr
zhubl
[root@ceph141 ~]# rados put sys.txt /etc/os-release -p zhubl
[root@ceph141 ~]# rados ls -p zhubl
sys.txt
[root@ceph141 ~]# rados -p zhubl stat sys.txt
zhubl/sys.txt mtime 2025-09-11T14:47:56.000000+0800, size 386
[root@ceph141 ~]# ceph osd map zhubl sys.txt
osdmap e80 pool 'zhubl' (2) object 'sys.txt' -> pg 2.486f5322 (2.2) -> up ([5,1,8], p5) acting ([5,1,8], p5)
[root@ceph141 ~]# rados -p zhubl rm sys.txt
[root@ceph141 ~]# rados -p zhubl ls
[root@ceph141 ~]# ceph osd map zhubl sys.txt
osdmap e80 pool 'zhubl' (2) object 'sys.txt' -> pg 2.486f5322 (2.2) -> up ([5,1,8], p5) acting ([5,1,8], p5)
[root@ceph141 ~]# rados df

池管理的官方文档: https://docs.ceph.com/en/squid/rados/operations/pools/
数据按照指定副本数量存储,默认为3副本。
相比于副本池而言,更加节省磁盘空间。有点类似于RAID5。
[root@ceph141 ~]# ceph osd pool ls
[root@ceph141 ~]# ceph osd lspools
[root@ceph141 ~]# ceph osd pool ls detail
[root@ceph141 ~]# ceph osd pool create xixi replicated
[root@ceph141 ~]# ceph osd pool create haha erasure
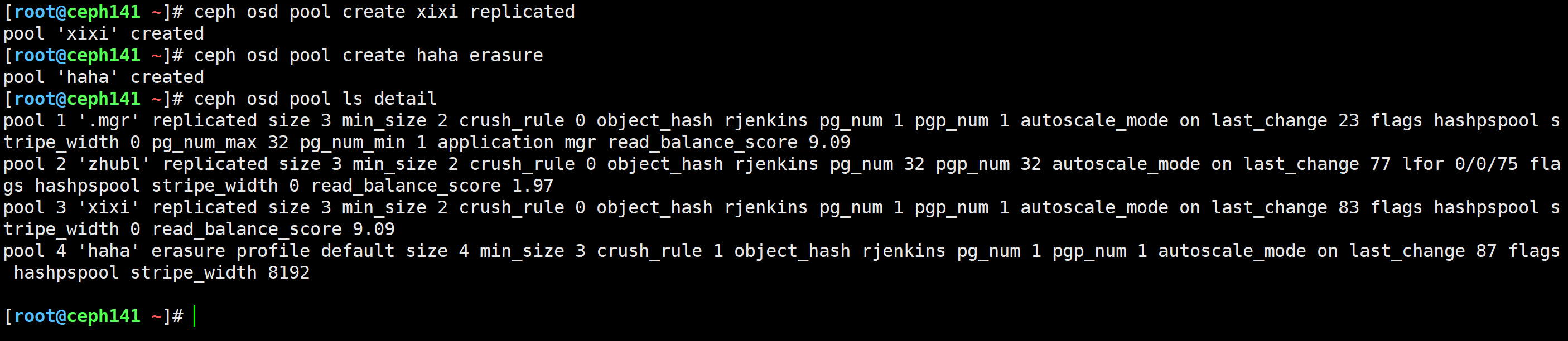
[root@ceph141 ~]# ceph osd pool set xixi size 2
[root@ceph141 ~]# ceph osd pool ls detail

[root@ceph141 ~]# ceph osd pool rename xixi hehe
[root@ceph141 ~]# ceph osd pool ls detail

[root@ceph141 ~]# rados df

[root@ceph141 ~]# ceph osd pool stats
[root@ceph141 ~]# ceph osd pool stats zhubl

[root@ceph141 ~]# ceph osd pool get hehe size
[root@ceph141 ~]# ceph osd dump | grep 'replicated size'

一旦一个存储池被删除,那么该存储池的所有数据都会被删除且无法找回。
因此为了安全起见,ceph有存储池保护机制,ceph支持两种保护机制: “nodelete"和"mon_allow_pool_delete”
nodelete:
一旦一个存储池被打上该标记,则意味着存储池不可被删除,默认值为false,表示可以被删除。
mon_allow_pool_delete:
告诉所有mon组件,可以删除存储池。默认值为false,表示不可以被删除。
生产环境中,为了安全起见,建议将存储池设置为nodelete的属性为"ture",mon_allow_pool_delete的值为false。
'nodelete’和’mon_allow_pool_delete’任意一种机制都具有一票否决权,如果想要删除一个存储池,2者都得允许删除,这就是ceph的存储池保护机制。
[root@ceph141 ~]# ceph osd pool ls
.mgr
zhubl
hehe
haha
[root@ceph141 ~]# ceph osd pool get hehe nodelete
nodelete: false
[root@ceph141 ~]# ceph tell mon.* injectargs --mon_allow_pool_delete=true
mon.ceph141: {}
mon.ceph141: mon_allow_pool_delete = ''
mon.ceph142: {}
mon.ceph142: mon_allow_pool_delete = ''
mon.ceph143: {}
mon.ceph143: mon_allow_pool_delete = ''
[root@ceph141 ~]# ceph osd pool delete hehe hehe --yes-i-really-really-mean-it
pool 'hehe' removed
[root@ceph141 ~]# ceph osd pool ls
.mgr
zhubl
haha
[root@ceph141 ~]# ceph tell mon.* injectargs --mon_allow_pool_delete=false
mon.ceph141: {}
mon.ceph141: mon_allow_pool_delete = ''
mon.ceph142: {}
mon.ceph142: mon_allow_pool_delete = ''
mon.ceph143: {}
mon.ceph143: mon_allow_pool_delete = ''
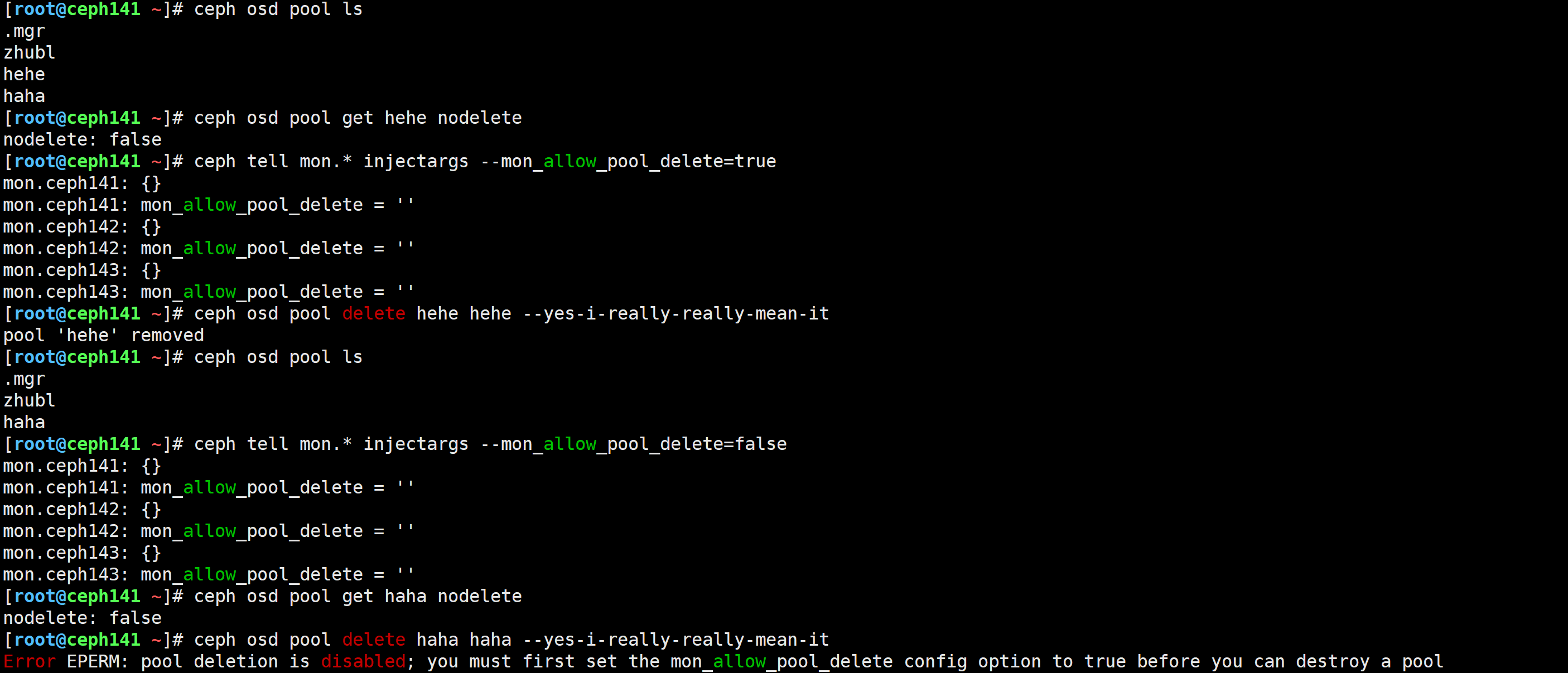
[root@ceph141 ~]# ceph osd pool get haha nodelete
nodelete: false
[root@ceph141 ~]# ceph osd pool delete haha haha --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
[root@ceph141 ~]#
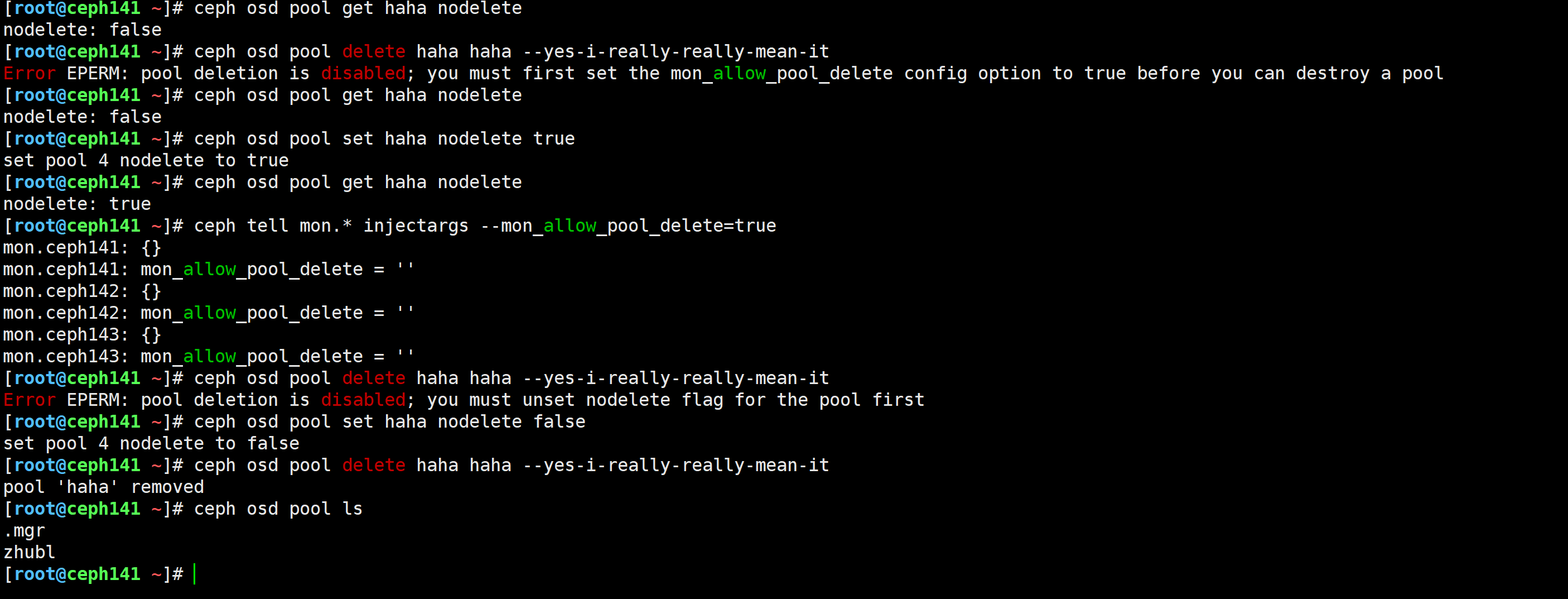
[root@ceph141 ~]# ceph osd pool get haha nodelete
nodelete: false
[root@ceph141 ~]# ceph osd pool set haha nodelete true
set pool 4 nodelete to true
[root@ceph141 ~]# ceph osd pool get haha nodelete
nodelete: true
[root@ceph141 ~]# ceph tell mon.* injectargs --mon_allow_pool_delete=true
mon.ceph141: {}
mon.ceph141: mon_allow_pool_delete = ''
mon.ceph142: {}
mon.ceph142: mon_allow_pool_delete = ''
mon.ceph143: {}
mon.ceph143: mon_allow_pool_delete = ''
[root@ceph141 ~]# ceph osd pool delete haha haha --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must unset nodelete flag for the pool first
[root@ceph141 ~]# ceph osd pool set haha nodelete false
set pool 4 nodelete to false
[root@ceph141 ~]# ceph osd pool delete haha haha --yes-i-really-really-mean-it
pool 'haha' removed
[root@ceph141 ~]# ceph osd pool ls
.mgr
zhubl
[root@ceph141 ~]#
参考链接:
https://docs.ceph.com/en/squid/rados/operations/placement-groups/
OSD数量 * 100
----------------- —> PG数量
pool存储池的size
假设你有9块磁盘,则配置如下
9*100
------- ----> 300PG
3
但是得到的结果是300,官方建议是2的次方,和300比较接近的是:256,因此集群的合理PG数量为256。
[root@ceph141 ~]# ceph osd pool set zhubl pg_num 2
[root@ceph141 ~]# ceph osd pool set zhubl pgp_num 2
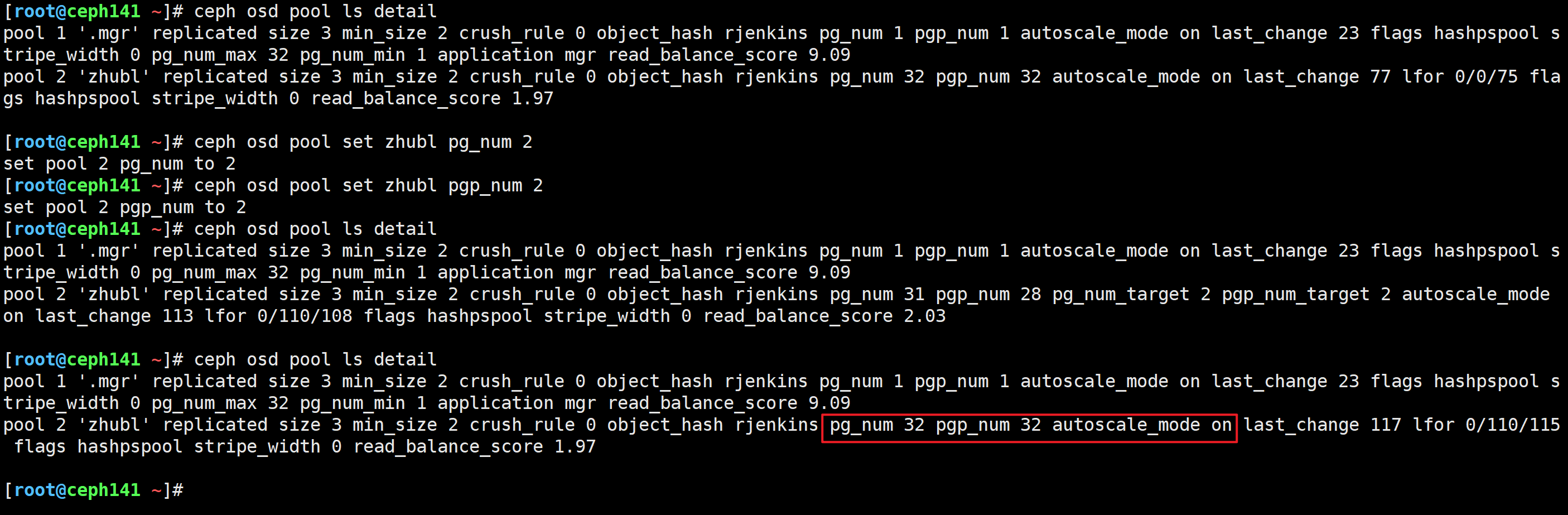
[root@ceph141 ~]# ceph osd pool set zhubl pg_num 2
set pool 2 pg_num to 2
[root@ceph141 ~]# ceph osd pool set zhubl pgp_num 2
set pool 2 pgp_num to 2
[root@ceph141 ~]# ceph osd pool ls detail
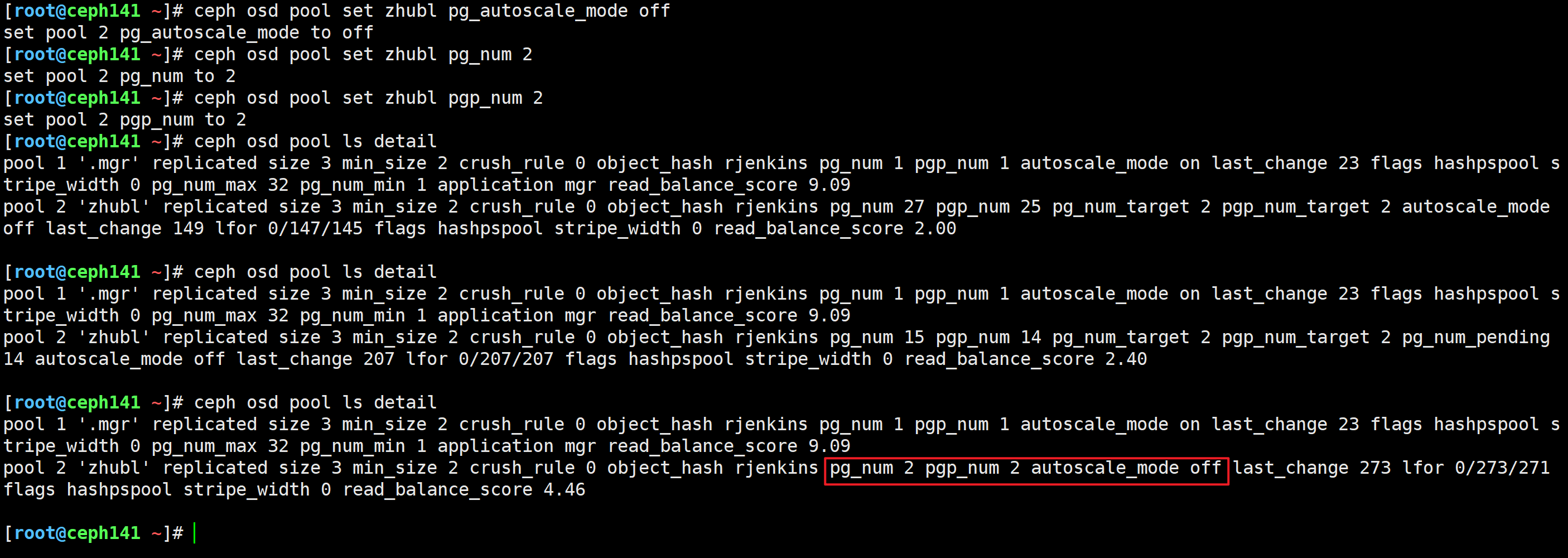
[root@ceph141 ~]# ceph osd pool create haha 128 128 --autoscale_mode off
[root@ceph141 ~]# ceph osd pool ls detail

pg: 一个存储池可以有多个pg,数据分布式存储在不同的pg中,pg和pgp数量要保持一致。
size: 数据存储几份,对于副本池而言,若不指定,则默认存储3副本。
min_size: 最小可用的副本数量,比如3副本,如果你设置为最小的副本数量为1,表示可以允许挂掉2个节点。但是如果你设置的为2,表示可以挂掉1个节点。
[root@ceph141 ~]# ceph osd pool create zhubaolin 8 8 replicated --autoscale_mode off --size 3
pool 'zhubaolin' created
[root@ceph141 ~]#
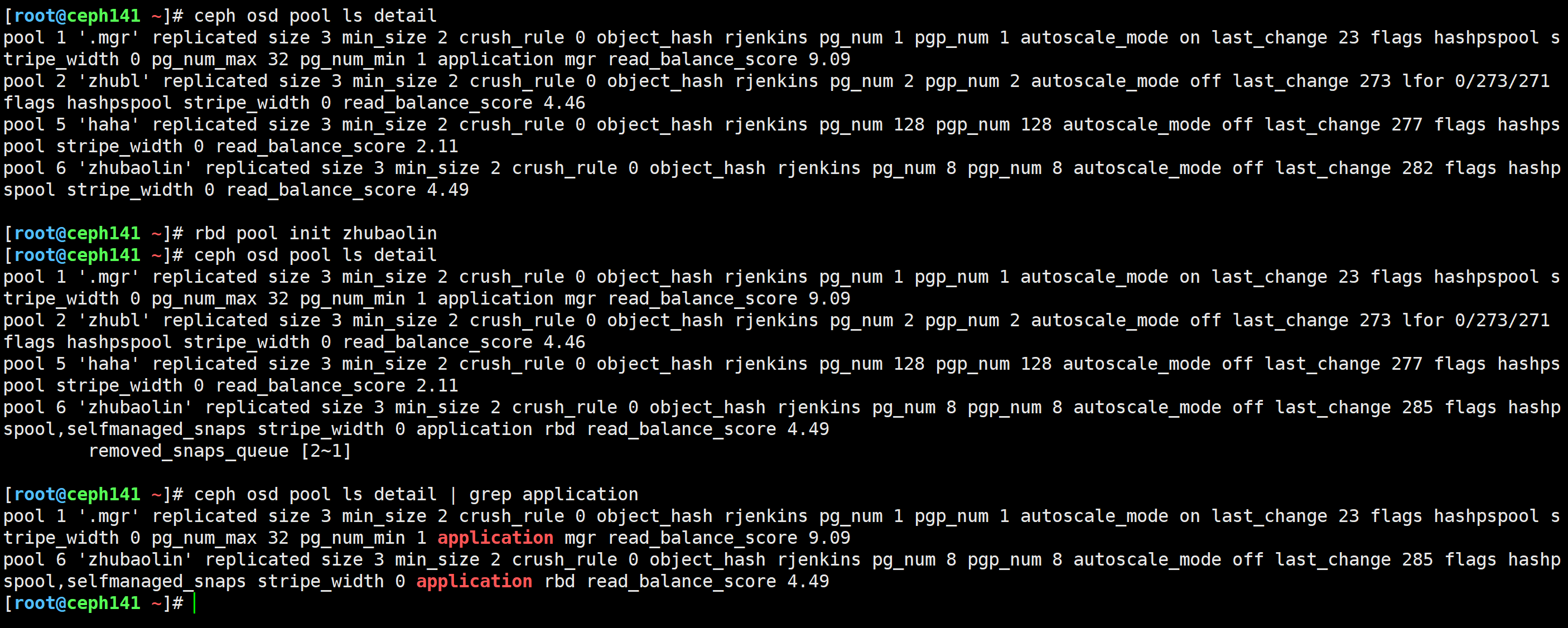
[root@ceph141 ~]# ceph osd pool ls detail
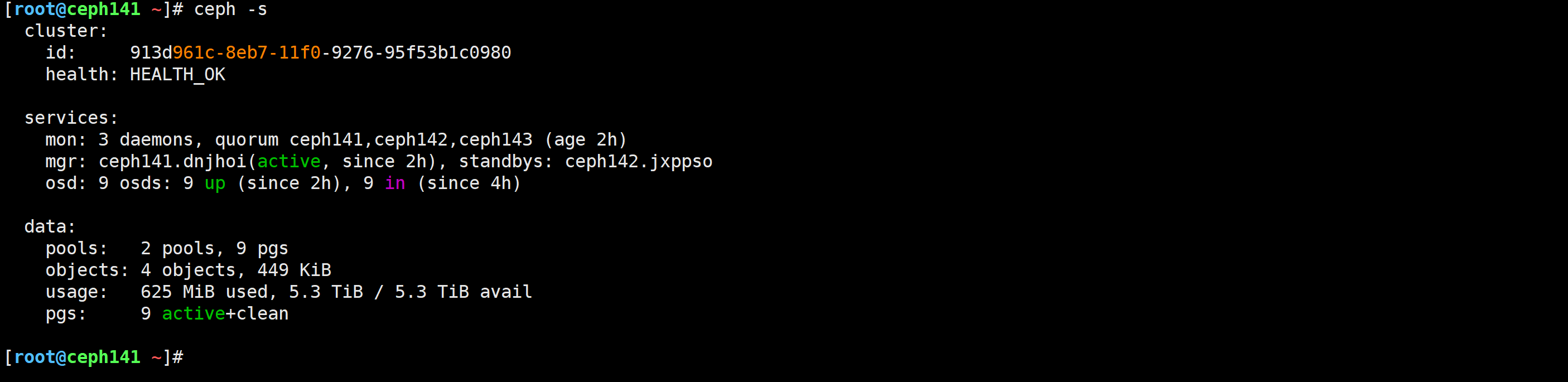
[root@ceph141 ~]# rbd pool init zhubaolin
[root@ceph141 ~]# ceph -s
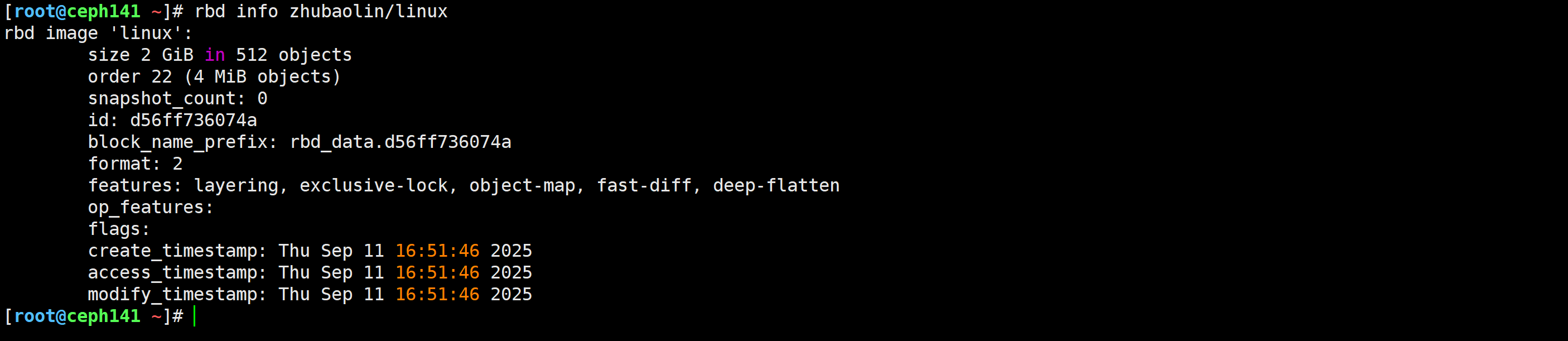
[root@ceph141 ~]# rbd create -s 2G zhubaolin/linux
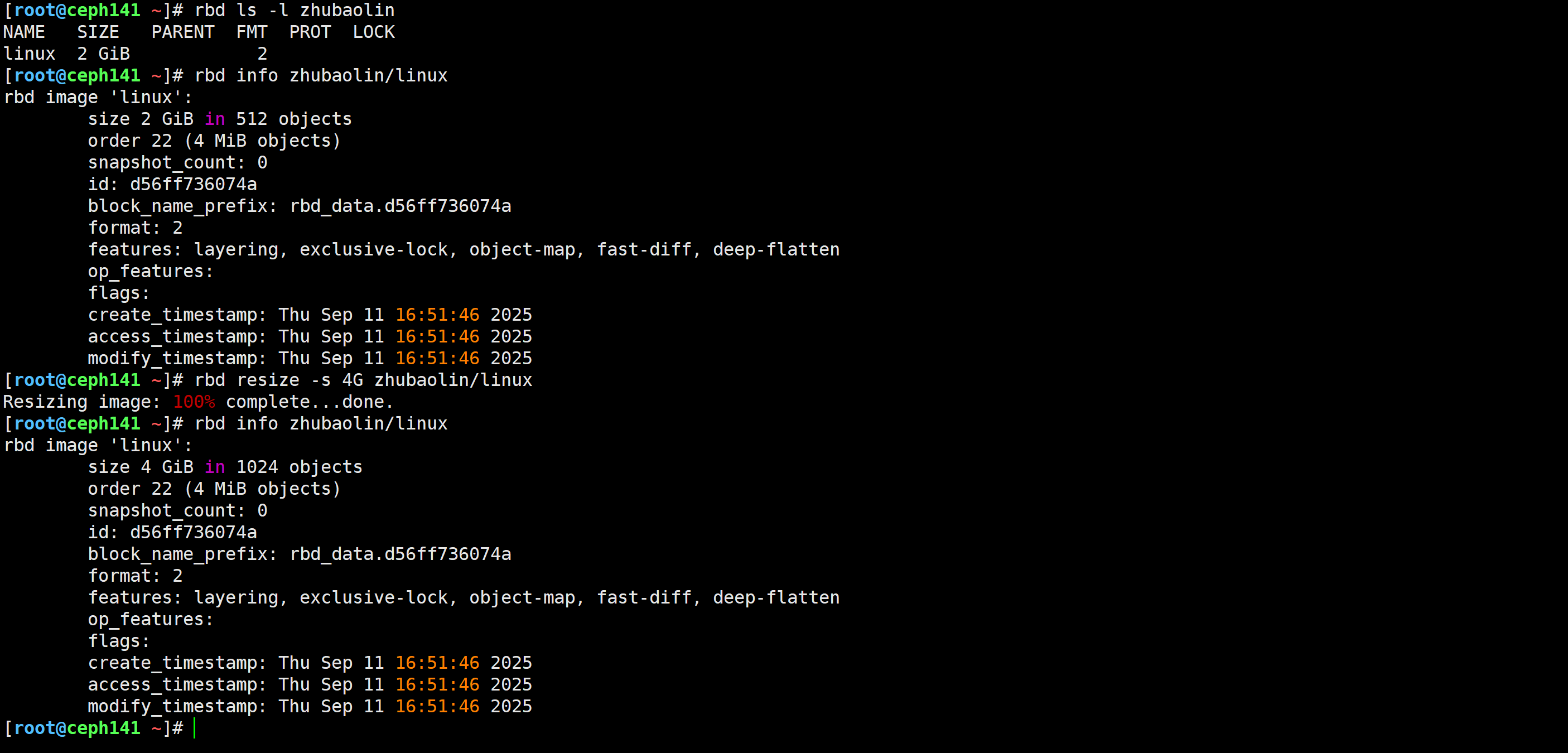
[root@ceph141 ~]# rbd ls -l zhubaolin

[root@ceph141 ~]# rbd info zhubaolin/linux
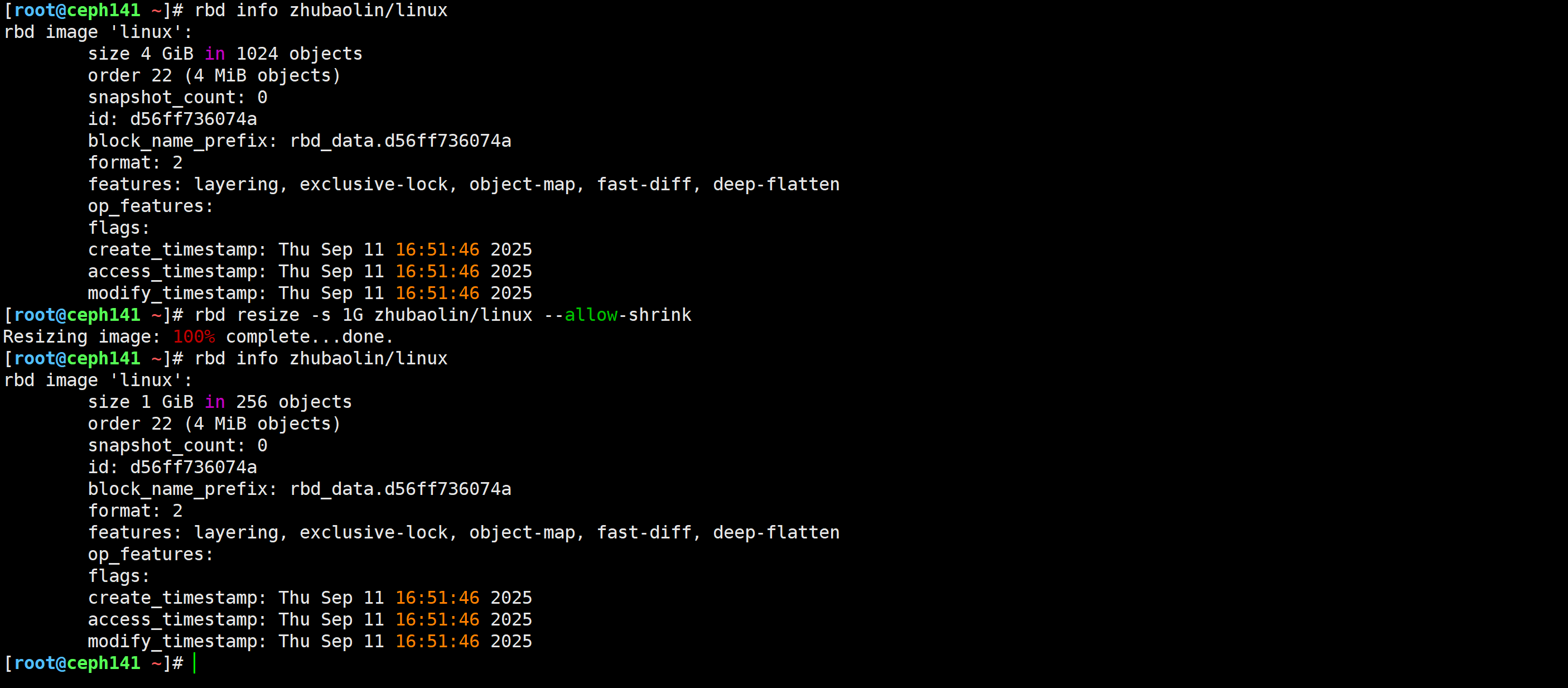
[root@ceph141 ~]# rbd resize -s 4G zhubaolin/linux
[root@ceph141 ~]# rbd resize -s 1G zhubaolin/linux --allow-shrink
[root@ceph141 ~]# rbd info zhubaolin/linux
[root@ceph141 /etc/rc3.d]# rbd rename -p zhubaolin linux LINUX

[root@ceph141 /etc/rc3.d]# rbd rm zhubaolin/LINUX
Removing image: 100% complete...done.

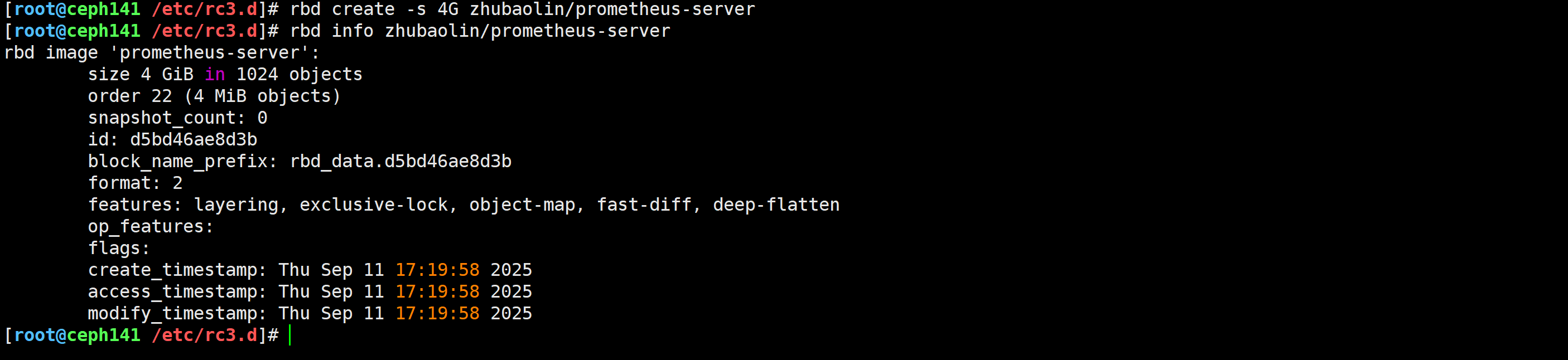
[root@ceph141 ~]# rbd create -s 4G zhubaolin/prometheus-server
[root@prometheus-server31 ~]# apt update
[root@prometheus-server31 ~]# apt -y install ceph-common
[root@prometheus-server31 ~]# ceph --version
[root@ceph141 ~]# scp /etc/ceph/{ceph.conf,ceph.client.admin.keyring} 10.0.0.31:/etc/ceph
[root@prometheus-server31 ~]# rbd map zhubaolin/prometheus-server
/dev/rbd0
[root@prometheus-server31 ~]#

[root@prometheus-server31 ~]# mkfs.ext4 /dev/rbd0
[root@prometheus-server31 ~]# mount /dev/rbd0 /mnt/

[root@prometheus-server31 ~]# cp /etc/os-release /mnt/

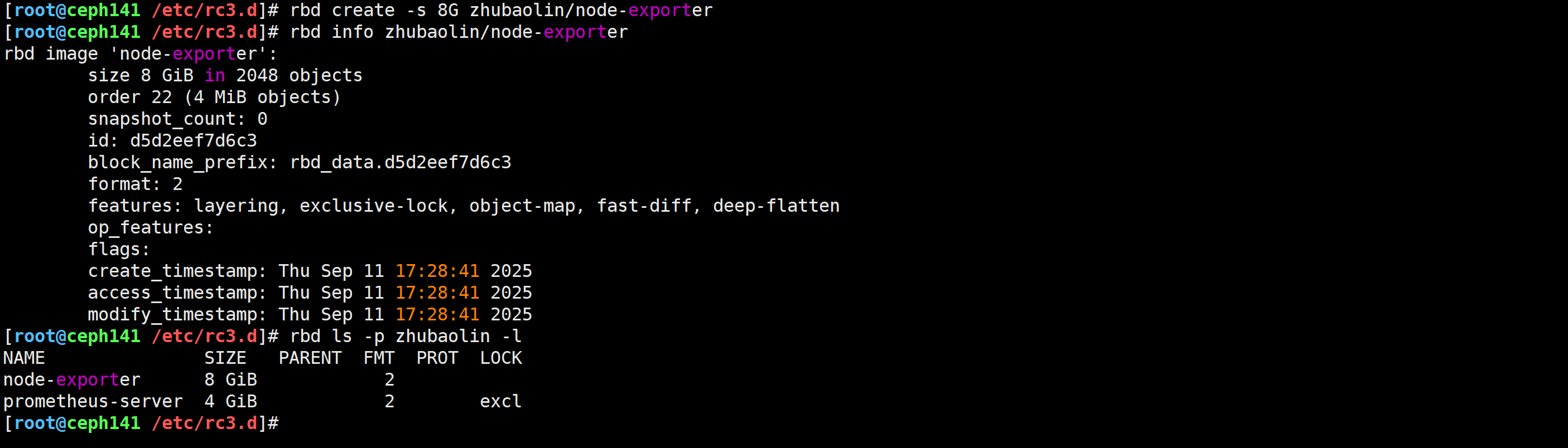
[root@ceph141 ~]# rbd create -s 8G zhubaolin/node-exporter
[root@prometheus-server31 ~]# rbd map zhubaolin/node-exporter

[root@prometheus-server31 ~]# mkfs.xfs /dev/rbd1
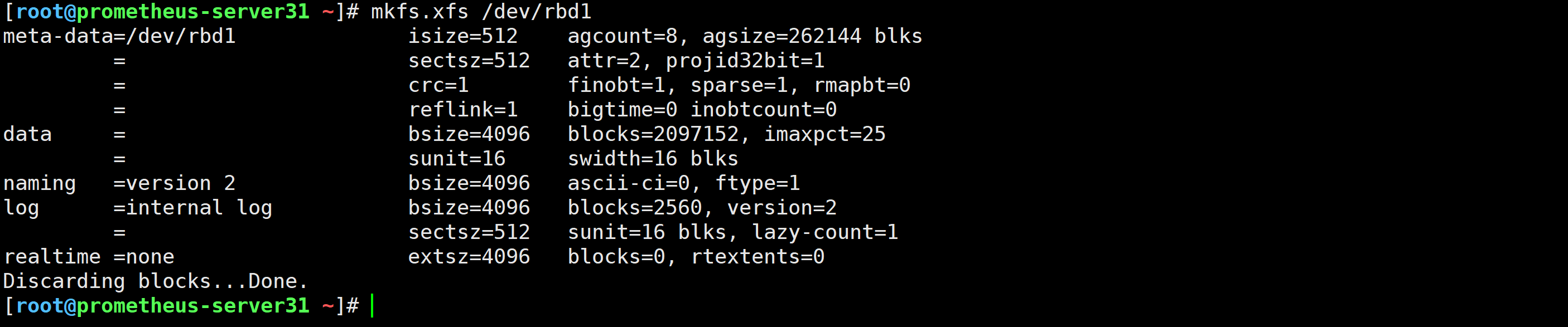
[root@prometheus-server31 ~]# mount /dev/rbd1 /opt/

[root@prometheus-server31 ~]# cp /etc/netplan/00-installer-config.yaml /opt/

[root@prometheus-server31 ~]# systemctl stop prometheus-server.service
[root@prometheus-server31 ~]# cd /app/tools/prometheus-2.53.4.linux-amd64/
[root@prometheus-server31 /app/tools/prometheus-2.53.4.linux-amd64]# ./prometheus --storage.tsdb.path="/mnt"
ll /mnt/

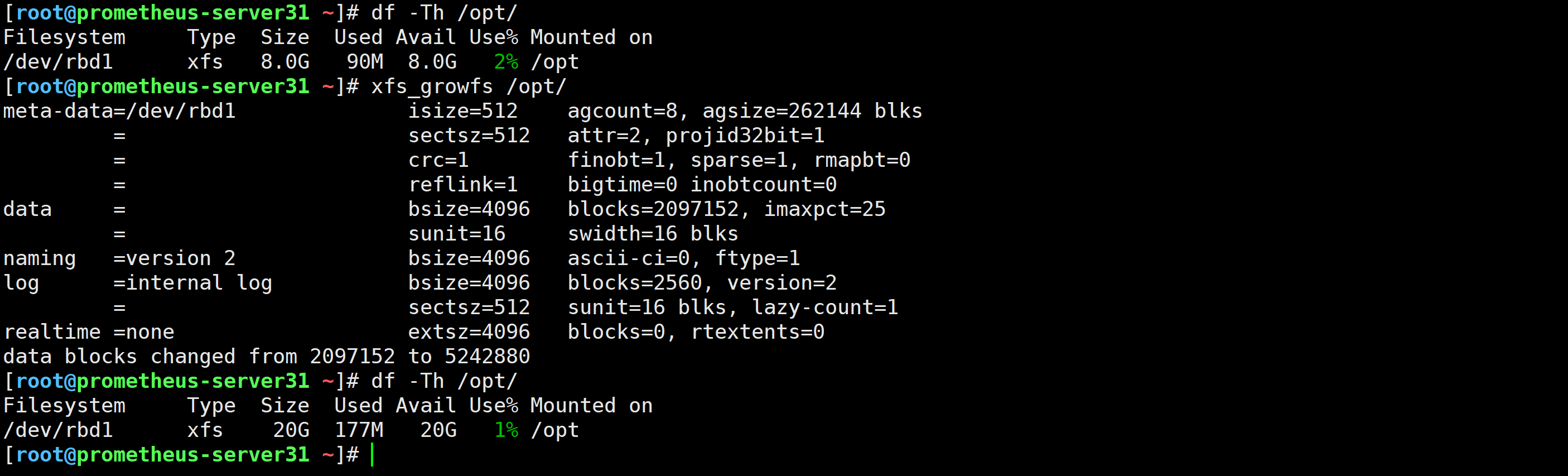
[root@ceph141 /etc/rc3.d]# rbd resize -s 10G zhubaolin/prometheus-server
Resizing image: 100% complete...done.
[root@ceph141 /etc/rc3.d]# rbd resize -s 20G zhubaolin/node-exporter
Resizing image: 100% complete...done.

[root@prometheus-server31 ~]# resize2fs /dev/rbd0
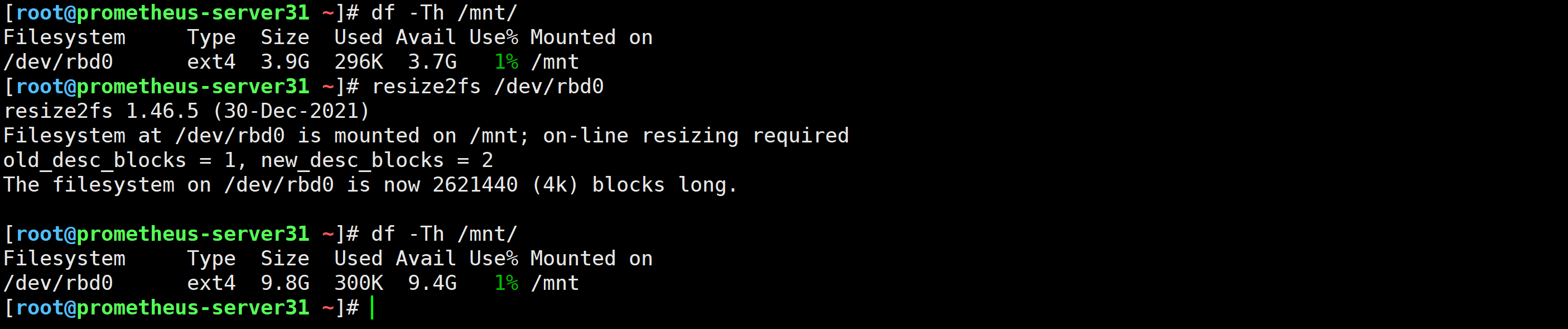
[root@prometheus-server31 ~]# xfs_growfs /opt/